What is a Sklearn pipeline? Today, we are going to learn about scikit-learn pipeline and its importance. To get the most out of machine learning (ML) models, many data science projects require some amount of data cleaning and preprocessing.
The following are some examples of frequent preprocessing or transformations:
- Eliminating outliers
- Normalizing or standardizing numerical variables
- Imputing missing values
- Categorical features encoding
A typical data science workflow goes like this:
- Obtaining the data for training
- Cleaning, preprocessing and transformation of the data
- Creation of a machine learning model and training it
- Analyzing and improving the model
- Cleaning/processing/transformation of new data
- Fitting the model to the new data in order to make predictions
Most times than not, the features in an ML problem are unlikely to be in the correct format. As a result, some preprocessing on the features is needed prior to the training of the model.
Missing value handling, numerical feature scaling, and categorical feature encoding are all frequent preprocessing activities. In some ways, the preprocessing techniques can be thought of as changing the characteristics.
As you may have noticed, data preprocessing is required at least twice in the workflow. How amazing it would be if we could automate this process & apply it to all future new datasets in order to save effort. That’s exactly what the Sklearn pipeline module provides.
Scikit-learn Pipeline
Now, let’s take a hard look at what is a Sklearn pipeline. Scikit-learn’s pipeline module is a tool that simplifies preprocessing by grouping operations in a “pipe”. It’s vital to remember that the pipeline’s intermediary step must change a feature.
According to scikit-learn, the definition of a pipeline class is: (to) sequentially apply a list of transforms and a final estimator. Intermediate steps of pipeline must implement fit and transform methods, and the final estimator only needs to implement fit.
Let’s create a new dataset (dummy) and create simple pipeline to understand statement stated above.
import numpy as np, pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
from sklearn.impute import SimpleImputer

c1 = np.random.randint(11, size=50)
c2 = np.random.randint(16, size=50)
c3 = np.random.random(50)
c4 = pd.Series([‘a’,’b’,’c’]).sample(50, replace=True)
#target var
target = np.random.randint(3, size=50)
#create dataframe
df = pd.DataFrame({
‘c1’:c1,
‘c2’:c2,
‘c3’:c3,
‘c4’:c4,
‘target’:target})

Let’s add some missing values in the data (except the target column):
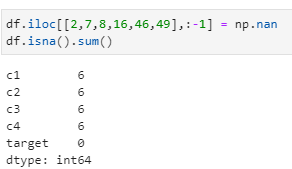
df.iloc[[2,7,8,16,46,49],:-1] = np.nan
df.isna().sum()
Different preprocessing strategies are required for numerical and categorical features. As a result, we’ll design distinct pipelines for numerical and categorical data, which we’ll then mix in a different transformer. The combined transformer and an ML model will be included in the final pipeline.
Let’s begin by implementing simple pipelines:
transform_num = Pipeline(steps= [(‘imputer’, SimpleImputer(strategy=’mean’)), (‘scaler’, MinMaxScaler())])

As a list of tuples, the transformations are supplied to pipeline’s steps parameter. A name and the transformation function are included in each tuple.
The transform_num fills mean in the missing values (SimpleImputer) and scales the values between 0 and 1 (MinMaxScaler).
transform_cat = Pipeline(steps= [(‘imputer’, SimpleImputer(strategy=’most_frequent’)), (‘encode’,OneHotEncoder(drop=’first’))])

The transform_cat uses the one-hot encoder to encode the categories and fills in the missing values with mode (most frequent) value of that column.
The transformers are now available. But they have yet to be applied to the features. We’ll utilize the scikit-learn column transformer module for this purpose.
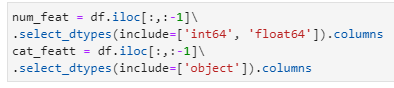
We must first establish two lists: one with numerical features and the other with category features, before we can create the column transformer object. Pandas’ “select dtypes” function is one way to accomplish this.
num_feat = df.iloc[:,:-1]\
.select_dtypes(include=[‘int64’, ‘float64’]).columns
cat_featt = df.iloc[:,:-1]\
.select_dtypes(include=[‘object’]).columns
Now, next step is to create column transformer:
from sklearn.compose import ColumnTransformer
pre_process = ColumnTransformer(transformers=[ (‘numeric’, transform_num, num_feat),(‘categorical’, transform_cat, cat_featt) ])
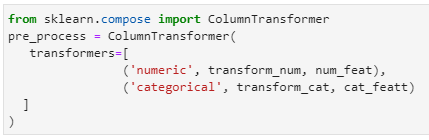
The next step is to combine the newly built column transformer with a machine learning model. For this procedure, we’ll set up a new pipeline.
from sklearn.linear_model import LogisticRegression
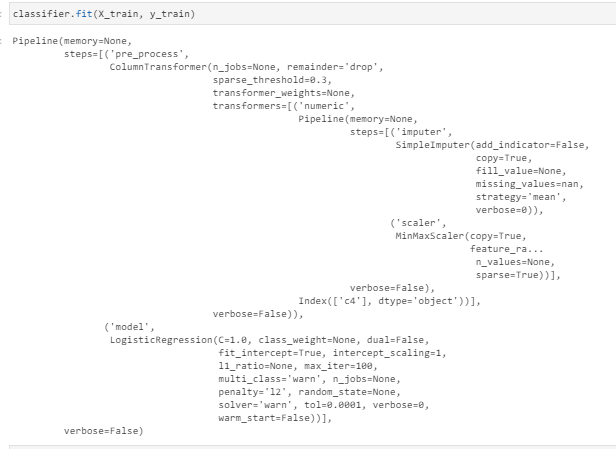
classifier = Pipeline([ (‘pre_process’, pre_process), (‘model’, LogisticRegression())])
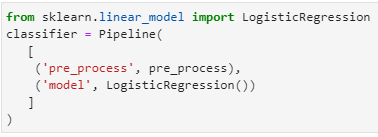
Let’s take a look at this new pipeline by breaking it down to its components.
The “classifier” is a pipeline that includes a “pre_process” transformer and a logistic regression model.
“transformer num” and “transformer cat” are two pipelines in the “preprocess” transformer.
On the “classifier” pipeline, we can now call the fit function directly. We’ll divide the dataset into train and test subgroups before training the classifier pipeline.
from sklearn.model_selection import train_test_split
X = df.drop(‘target’, axis=1)
y = df[‘target’]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)

Let’s fit the model.
classifier.fit(X_train, y_train)
Summary
The fundamental benefit of using pipelines is that they make preprocessing easier by grouping several actions into a single pipeline. Pipelines can also be used to pick models. For example, the pipeline built in this chapter can be used to experiment with different kinds of models.