This article contains affiliate links. For more, please read the T&Cs.

Scraping Yahoo with this simple and understandable tutorial that teaches a barebones approach using Python for web scraping. We’ll explore several critical Python libraries for extracting data from websites such as mechanize & BeautifulSoup along with using the data manipulation library Pandas to manage our data.
To scrape Yahoo, we need a few things first.
Import Your Libraries
The most critical libraries in how we’re going to scrape are Mechanize and BeautifulSoup. Pandas, datetime, and Numpy are all useful to us once we have extracted the data from the site itself.
If you don’t have these libraries installed, you must get those from their official source documentation, linked above. Once they’re installed, we’ll need to import the libraries into our script or Jupyter Notebook.
from mechanize import Browser
from bs4 import BeautifulSoup as BS
import pandas as pd
import datetime, random
import numpy as npUsing Beautiful Soup & Mechanize
Mechanize is ultimately the backbones of the scraping technology and allows us to emulate a browser of our choosing to pull down the data we want using Beautiful Soup.
In our use case, we set the user_agent used by the mechanize Browser function to Google Chrome and Firefox as fixed variables
url = "https://www.yahoo.com/"
user_agent = ['Google Chrome','Firefox']We then have to set the details of the mechanize Browser object with handles for robots, referer, and refresh. See the Mechanize documentation as to why we need these items.
I then add the random choice of user-agent as I’ve found that often I will get blocked from a URL when trying to scrape if I use the same user_agent over and over – which is a smart security feature from the websites perspective.
Once we’re here, we can use the Browser object to read the HTML on our URL into the beautiful soup object for us to extract data out of.
def get_soup(url,user_agent):
br = Browser()
br.set_handle_robots(False)
br.set_handle_referer(False)
br.set_handle_refresh(False)
u_a = random.choice(user_agent)
br.addheaders = [('User-agent', u_a)]
br.open(url)
soup = BS(br.response().read())
return soupInspecting the Yahoo! Widget
While getting to know beautiful soup, you have to have a basic knowledge of HTML and CSS to understand how to extract the correct data from within the website you’re scraping.
NOTE: As of the posting of this post (May, 2020) the item that we have in the HTML now will likely change over time
The first thing we need to do when you’re identifying which objects we want to store is find the actual trending widget within the HTML on Yahoo.
The quick way of doing this is to select Inspect Element on the first trending item in the trending widget
What you’ll see from the inspect element feature is something like this.

We’ve highlighted the class called “trending-list” which is the object that contains the full list of the trending objects – the one we see first in this list is the title “Lily Collins”. This is iterated through the next 9 items in the widget under the “li” items.
Extract Trend Terms
Now that we’ve obtained our target object from Beautiful Soup and know what we need to extract from the soup object, we can then pull the data from a specified list using the find_all function to pull out our specific list object.
We know that the list items are stored under a “li” HTML object and it’s under the class “trending-list” – these are the variables we need to insert into the find_all() function to extract what we’re looking for.
trend_list = soup.find_all("li", class_="trending-list")Unfortunately the output will look like a big mess as an output of the trend_list as seen below:
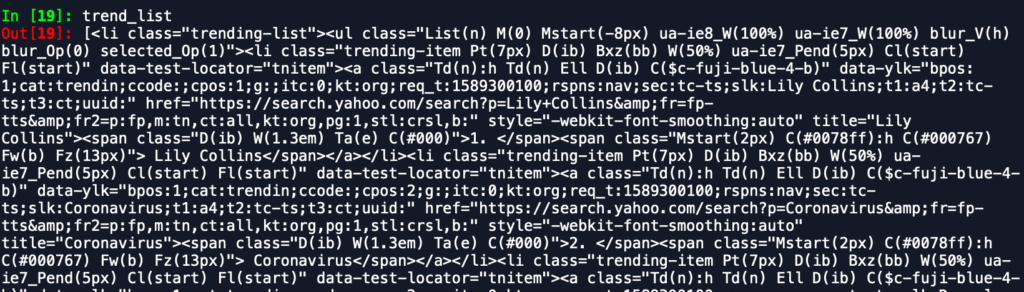
We can’t do much with this object so we will need to extract the specific text and links we’re interested in within this object. To do this, we’ll want to extract the specific text object using the get_text function in beautiful-soup.
text = trend_list[0].get_text().split(". ")[1:]This variable will contain a list of our text objects within the trending widget:
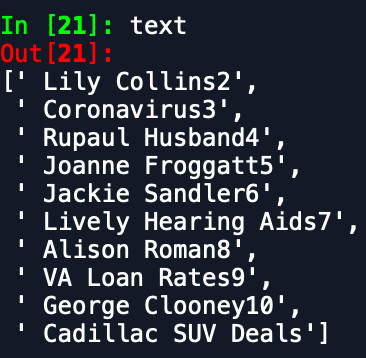
We won’t get into some of the other data we want to extract and how to do it, but it includes the rank, text, and link that the widget shows or points to.
All of that is covered in the below code. We extract these three objects separately and add them to a Pandas dataframe object. We then add the timestamp we pulled the data on (just for tracking purposes in case we pull the data multiple times into the same file).
def get_trending_now(soup):
trend_list = soup.find_all("li", class_="trending-list")
rank = np.arange(10)+1
pull_time = [datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") for r in rank]
text = trend_list[0].get_text().split(". ")[1:]
links = [a['href'] for a in trend_list[0].find_all('a', href=True)]
df = pd.DataFrame({"rank":rank,"text":text,"url":links,"time":pull_time})
df['time'] = pd.to_datetime(df['time'])
return dfNow that we have our soup object and our parser for the soup to extract the data in the trending widget specifically, we can execute the functions to get our data output.
soup = get_soup(url,user_agent)
df_trend = get_trending_now(soup)Other Stuff to Scrape
There is a lot on the Yahoo! front page that could be of value to you depending on what you want to extract (even horoscopes).
Some of the main items are covered below:
The News Feed
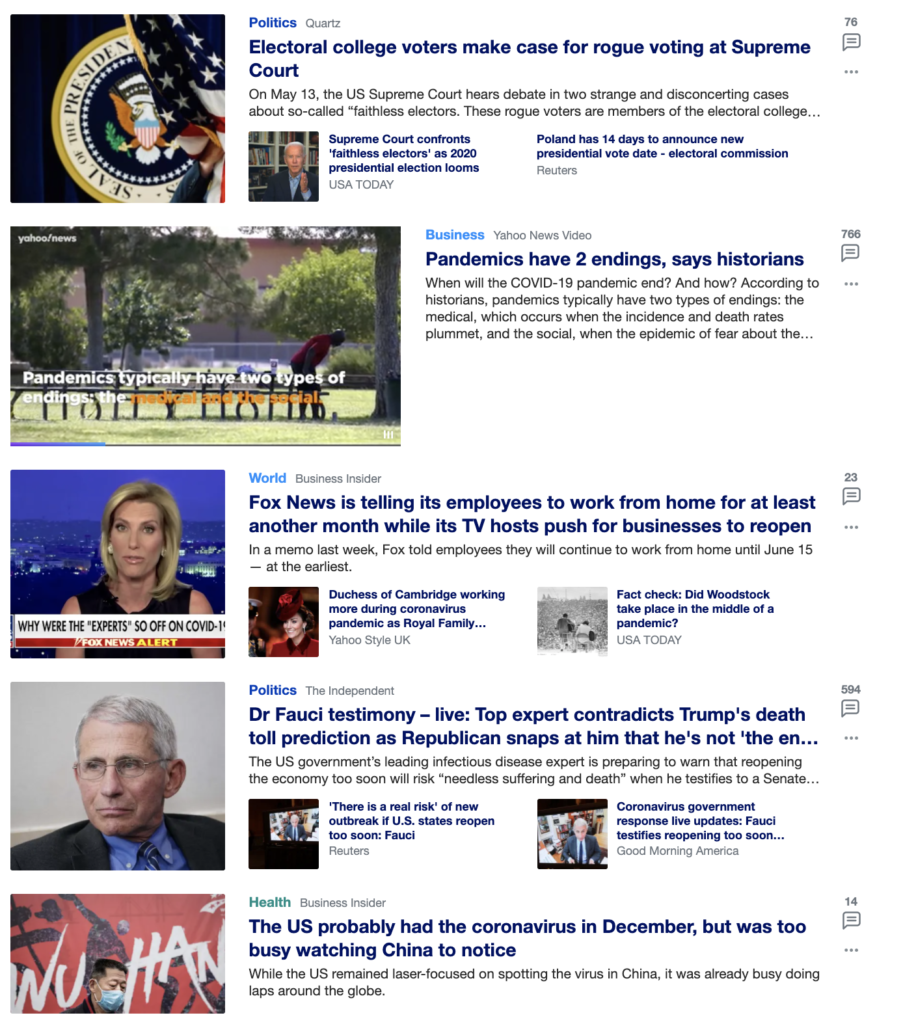
The news feed is actually quite interesting as it is sometimes localized based on where you’re pulling the data from – i.e. you’ll get very different feeds depending on where you live, for instance in India, you’re going to get Bollywood items in your feed of celebrities.
We can scrape the “List(n) P(0) stream-items” class to get this data.

Get News Sub-Feature

Let’s say you’re interested in the other featured news stories, you can access these by scraping the objects below class and getting all the li objects using the get_text() feature.
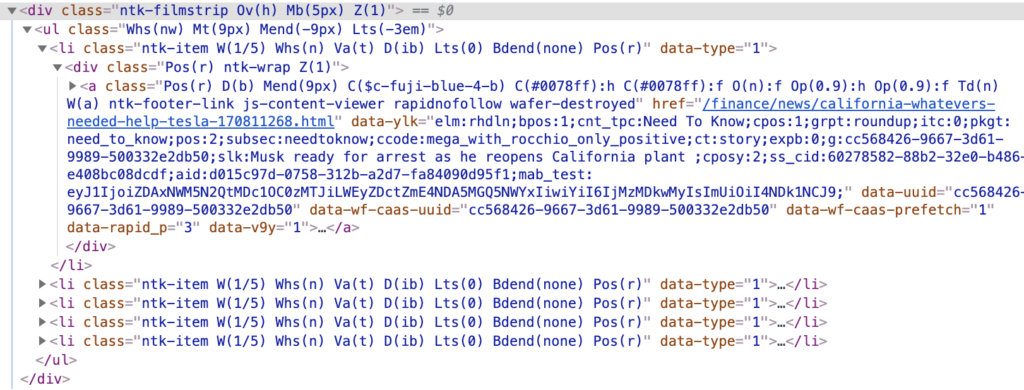
Summary
Whatever the reason is that you’re interested in scraping Yahoo!’s front-page, it’s actually an easy process to setup. My entire script to do this for the Trending widget in less than 50 lines of code.
Beautiful Soup and Mechanize are the backbones of easy to use with Python to setup a scraper.
We hope you enjoyed this post and feel free to leave us a comment if you have questions or critiques to this tutorial.
For more detail on how to scrape websites in detail, we recommend checking out Web Scraping with Python from O’Reilly.
See the full code below from this article:
from mechanize import Browser
from bs4 import BeautifulSoup as BS
import pandas as pd
import datetime, random
import numpy as np
### Parsed URL:
url = "https://www.yahoo.com/"
user_agent = ['Google Chrome','Firefox']
#FUNCTIONS
def get_soup(url,user_agent):
br = Browser()
br.set_handle_robots(False)
br.set_handle_referer(False)
br.set_handle_refresh(False)
u_a = random.choice(user_agent)
br.addheaders = [('User-agent', u_a)]
br.open(url)
soup = BS(br.response().read())
return soup
def get_trending_now(soup):
trend_list = soup.find_all("li", class_="trending-list")
rank = np.arange(10)+1
pull_time = [datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") for r in rank]
text = trend_list[0].get_text().split(". ")[1:]
links = [a['href'] for a in trend_list[0].find_all('a', href=True)]
df = pd.DataFrame({"rank":rank,"text":text,"url":links,"time":pull_time})
df['time'] = pd.to_datetime(df['time'])
return df
#EXECUTION
print("Let's make soup")
soup = get_soup(url,user_agent)
print("It's good")
df_trend = get_trending_now(soup)
print("What's in this soup, it's great!")
df_tread.head()